-
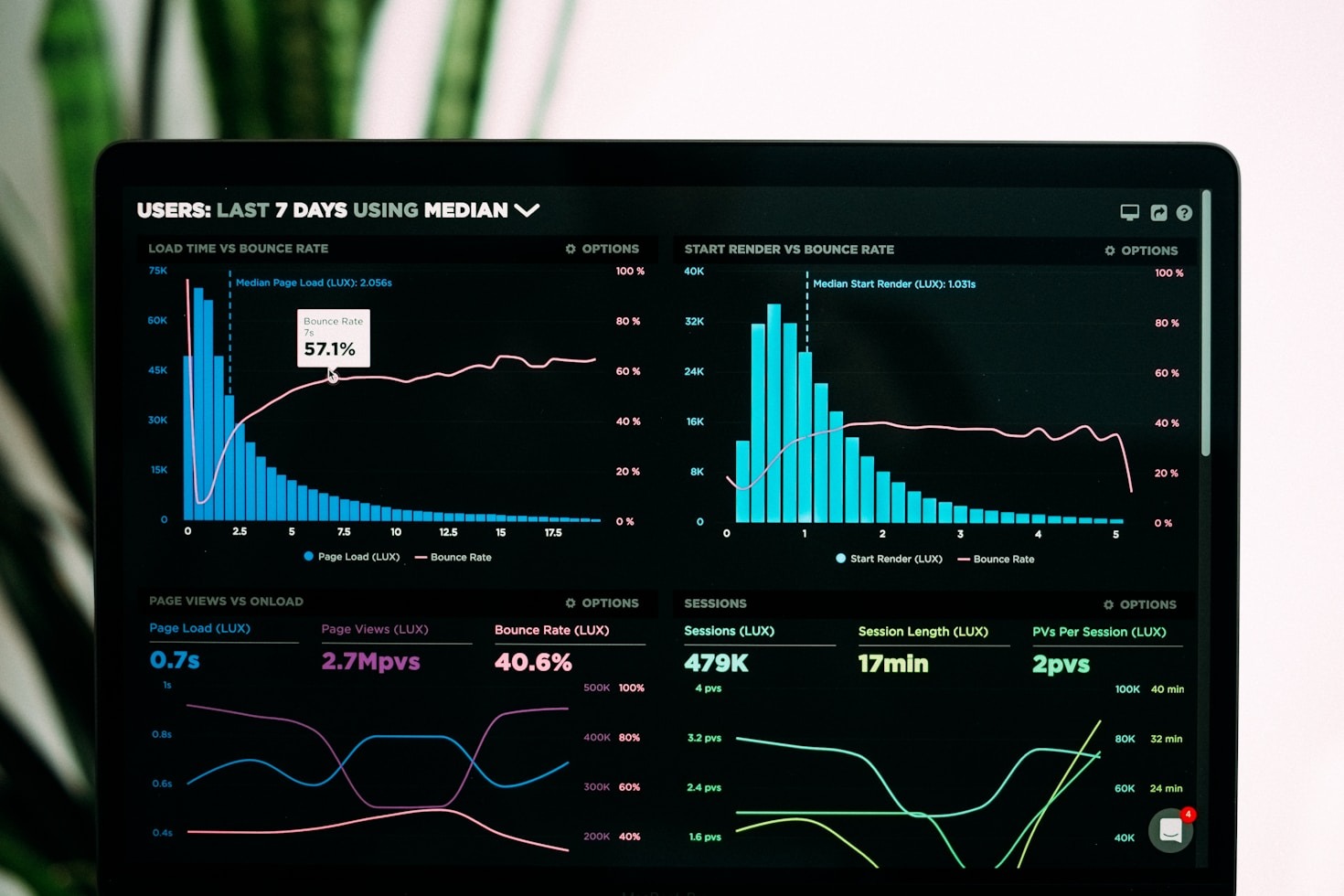
In the world of data engineering, speed and efficiency are not just nice‑to‑have—they’re essential. Whether you’re building real‑time streaming pipelines, orchestrating nightly batch jobs, or maintaining a data lakehouse, the difference between a system that scales gracefully and one that stalls under load often comes down to how well you’ve tuned your architecture. This post…
-
1. Why Future‑Proofing Matters Data volumes are exploding, regulations are tightening, and new technologies (AI, edge computing, quantum) are reshaping how we collect, store, and analyze information. A data architecture that works today can become a bottleneck tomorrow. Future‑proofing isn’t about predicting every trend; it’s about building flexibility, resilience, and scalability into the foundation so…
-

How a Fortune‑500 retailer revamped its data governance framework to unlock value, ensure compliance, and accelerate innovation 1. The Problem 1.1 Fragmented Data Silos A global retailer with 200+ stores and 5 TB of daily transactional data was struggling to get a unified view of its operations. Data lived in disparate systems—POS, e‑commerce, supply‑chain, marketing, and…
-

Practical tactics that turn slow, brittle pipelines into high‑performance, elastic data engines 1. Why Speed and Scale Matter If your pipeline can’t grow with data volume or adapt to changing workloads, you’ll hit a bottleneck before you hit the next revenue milestone. 2. The End‑to‑End Pipeline Blueprint Layer Typical Tools Key Performance Levers Ingestion Kafka,…
-

In the past decade, data teams have wrestled with a classic dilemma: how to combine the flexibility of a data lake with the reliability of a data warehouse. The answer that’s reshaping analytics, machine‑learning, and real‑time decision‑making is the Lakehouse. This hybrid architecture unifies storage, governance, and compute in a single platform, enabling organizations to treat all…
-

TL;DR – In 2025, data observability is no longer a nice‑to‑have; it’s a prerequisite for any data‑driven organization. By combining real‑time telemetry, AI‑driven anomaly detection, and a unified metadata layer, you can turn raw data pipelines into self‑healing, auditable systems that scale with your business. 1. Why Observability Matters Problem Impact Observability Solution Data quality drifts…
-

In today’s world, the ability to capture, process, and act on data as it arrives is no longer a luxury—it is a necessity. Whether you are building a recommendation engine that must respond to a user’s click in real time, monitoring sensor data from a fleet of vehicles, or feeding a fraud‑detection system with every…
-
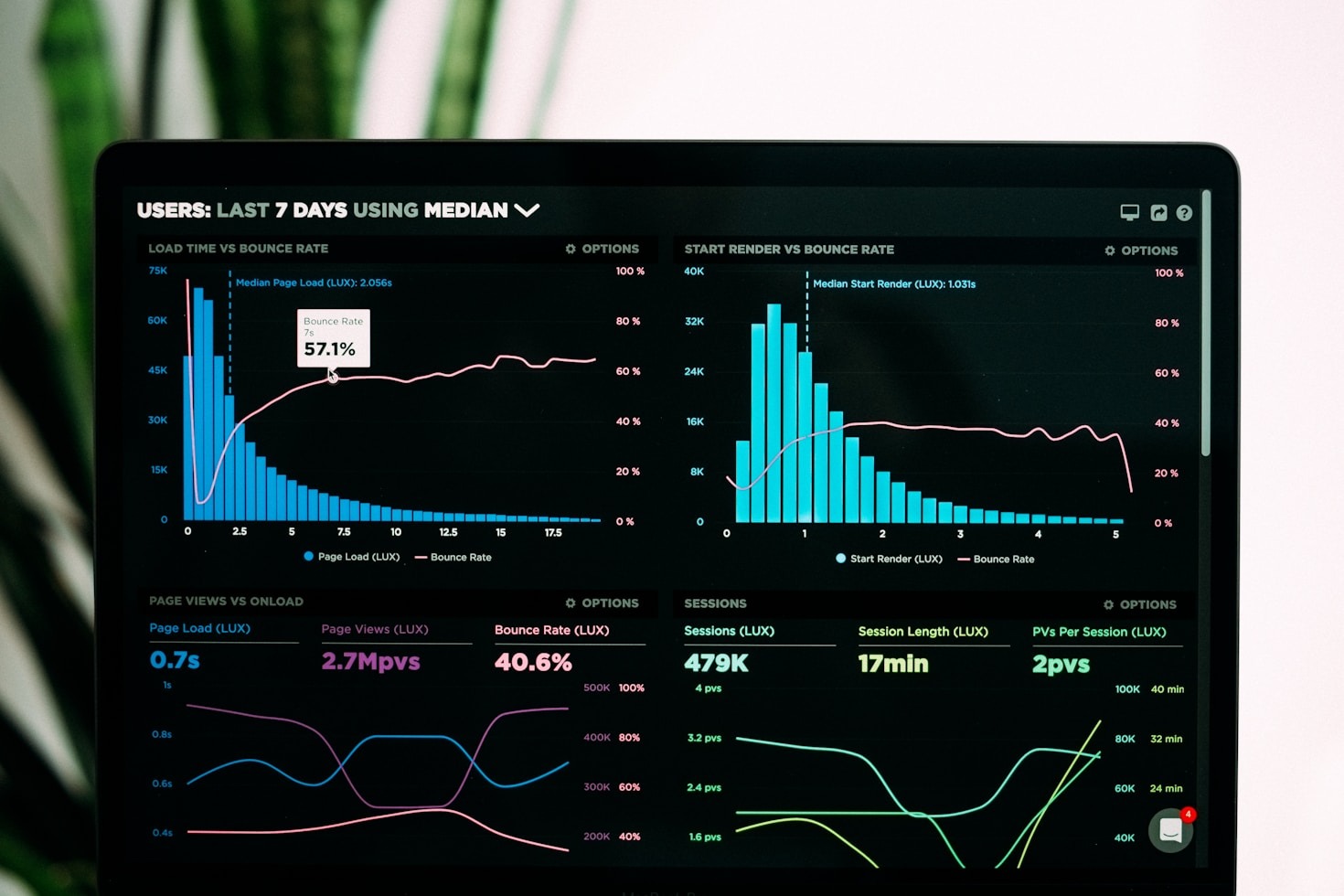
In a world where data is the new oil, the pipelines that move, clean, and enrich that oil are the engines of modern business. A robust data pipeline is more than a collection of scripts; it is a resilient, observable, and maintainable system that can grow with your organization’s needs. Below are five foundational principles…
-
A quick‑reference guide that covers the most effective techniques, tools, and best‑practice patterns for squeezing every bit of speed and efficiency out of your data pipelines. 1. Core Tuning Pillars Pillar What to Optimize Typical Metrics Ingestion Throughput, latency, back‑pressure Record rate, consumer lag, batch size Processing CPU, memory, shuffle, state Executor utilization, GC pause,…
-
(A practical playbook for building, maintaining, and scaling data quality & compliance) 1. Why Data Governance Matters 2. Core Pillars of a Governance Program Pillar What It Covers Typical Deliverables Data Catalog & Metadata Discovery, lineage, schema, ownership Catalog UI, automated lineage graphs Data Quality Accuracy, completeness, consistency, timeliness Validation rules, dashboards, alerts Data Security…